Contents
Overview
The release of BERT by Google in October 2018 marked a significant milestone in the development of natural language processing (NLP) models. Developed by researchers at Google, including Jacob Devlin and Ming-Wei Chang, BERT was designed to learn contextual, latent representations of tokens in their context, similar to ELMo and GPT-2. BERT's innovative approach to learning has found applications in many NLP tasks, such as coreference resolution and polysemy resolution, and has been used by companies like Microsoft and Facebook.
💻 How It Works
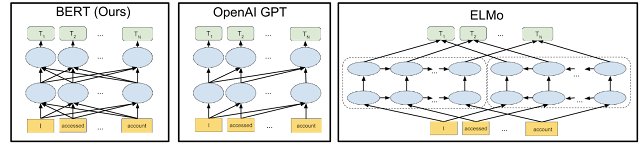
BERT's architecture is based on the encoder-only transformer architecture, which allows it to learn complex patterns in language data. The model is trained using a combination of masked token prediction and next sentence prediction, which enables it to learn contextual representations of tokens. BERT has been compared to other language models, such as Transformer and RoBERTa, and has been shown to outperform them in many NLP tasks. The development of BERT was influenced by earlier models, such as Word2Vec and GloVe, and has in turn influenced the development of newer models, such as DistilBERT and ALBERT.
🌐 Cultural Impact
The release of BERT has had a significant impact on the NLP community, with many researchers and developers using the model as a baseline for their own experiments. BERT has also been used in a variety of applications, including question answering, sentiment analysis, and text classification, and has been integrated into popular NLP libraries such as Hugging Face Transformers and Stanford CoreNLP. The study of BERT has also spawned the field of 'BERTology', which attempts to interpret what is learned by BERT, and has been explored by researchers at universities such as Stanford University and MIT.
🔮 Legacy & Future
The legacy of BERT continues to shape the development of NLP models, with many researchers building on the foundations laid by BERT. The model's impact can be seen in the development of newer models, such as T5 and Longformer, which have been designed to address some of the limitations of BERT. As NLP continues to evolve, it is likely that BERT will remain an important baseline for many years to come, and its influence can be seen in the work of companies like Google and Amazon.
Key Facts
- Year
- 2018
- Origin
- Category
- technology
- Type
- technology
Frequently Asked Questions
What is BERT?
BERT is a language model developed by Google that uses bidirectional encoder representations from transformers to learn contextual, latent representations of tokens. It was released in October 2018 and has since become a ubiquitous baseline in natural language processing experiments. BERT has been used by companies like Microsoft and Facebook, and has been compared to other language models, such as Transformer and RoBERTa.
How does BERT work?
BERT works by using a combination of masked token prediction and next sentence prediction to learn contextual representations of tokens. The model is trained on a large corpus of text data and uses the encoder-only transformer architecture. BERT has been shown to outperform other language models in many NLP tasks, and has been used in a variety of applications, including question answering and sentiment analysis. The development of BERT was influenced by earlier models, such as Word2Vec and GloVe, and has in turn influenced the development of newer models, such as DistilBERT and ALBERT.
What is the impact of BERT on the NLP community?
The release of BERT has had a significant impact on the NLP community, with many researchers and developers using the model as a baseline for their own experiments. BERT has also been used in a variety of applications, including question answering, sentiment analysis, and text classification, and has been integrated into popular NLP libraries such as Hugging Face Transformers and Stanford CoreNLP. The study of BERT has also spawned the field of 'BERTology', which attempts to interpret what is learned by BERT, and has been explored by researchers at universities such as Stanford University and MIT.
What are the limitations of BERT?
While BERT has been shown to be highly effective in many NLP tasks, it also has some limitations. One of the main limitations of BERT is its size, which can make it difficult to train and deploy. BERT also requires a large amount of computational resources, which can be a challenge for some researchers and developers. Additionally, BERT has been shown to be vulnerable to certain types of attacks, such as adversarial attacks, which can compromise its performance. Despite these limitations, BERT remains a widely used and influential model in the NLP community, and its influence can be seen in the work of companies like Google and Amazon.
What is the future of BERT?
The future of BERT is likely to be shaped by the ongoing development of newer models, such as T5 and Longformer, which have been designed to address some of the limitations of BERT. As NLP continues to evolve, it is likely that BERT will remain an important baseline for many years to come, and its influence can be seen in the work of companies like Google and Amazon.